Trino includes Hive connector to access Hive data warehouse. Warehouse data is stored in the Hadoop Distributed File System (HDFS) or in S3 compatible storages. Data files located in Hive warehouse are in varieties of formats and data size can be enormous. Trino uses Hive metastore to discover schemas and tables in undelaying data files and runs its own query engine. Kerberos authentication with keytab is applied to access HDFS and Hive metastore.
The sample is based on Starburst 343-e open source distribution and adopted to 393-e version, Cloudera CDH 5.7.0 and RHEL 7 Linux distribution.
1. Extract setup files from Cloudera CDH and copy to Trino nodes
- Open Cloudera Manager.
- Click on Hive service and then select Download Client Configuration in Actions button.
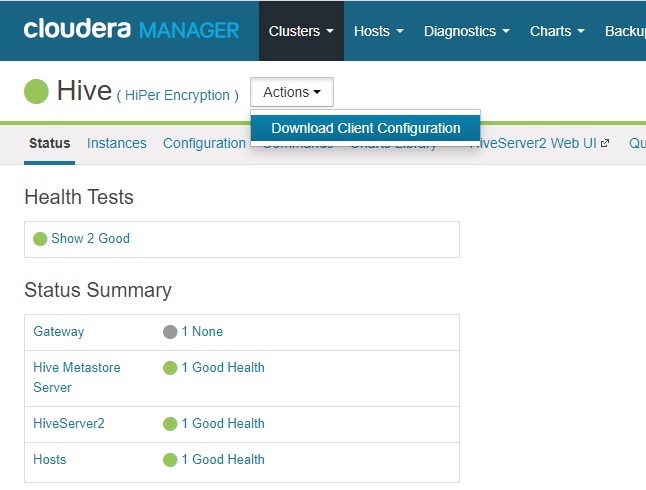
Extract
core-site.xmlandhdfs-site.xmlfiles fromhive-clientconfig.zipdownloaded archive.Copy files to
/etc/trinofolder in Trino nodes.
2. Copy Kerberos setup file from Cloudera CDH host to Trino nodes
The file name is krb5.conf and it is located in /etc folder on Cloudera CDH host and it has to be copied to /etc folder in Trino nodes.
3. Create keytab file
The file is supposed to be provided by the security team of your company. Follow the information in Create keytab File for Kerberos Authentication in Windows or Create keytab File for Kerberos Authentication in Linux article.
Distribute principal_name.keytab created file to /etc/trino folder in Trino nodes.
4. Create connector file
connector.name=hive
hive.metastore.uri=thrift://hive_meta_store_host.sample.com:9083
hive.metastore.authentication.type=KERBEROS
hive.metastore.service.principal=hive/_HOST@SAMPLE.COM
hive.metastore.client.principal=principal_name@SAMPLE.COM
hive.metastore.client.keytab=/etc/trino/principal_name.keytab
hive.hdfs.authentication.type=KERBEROS
hive.hdfs.trino.principal=principal_name@SAMPLE.COM
hive.hdfs.trino.keytab=/etc/trino/principal_name.keytab
hive.config.resources=/etc/trino/core-site.xml,/etc/trino/hdfs-site.xml
- Hive metastore host: hive_meta_store_host.sample.com
- Hive metastore default port: 9083
- Company domain: SAMPLE.COM
- Account name in keytab: principal_name
- Keytab location and name: /etc/trino/principal_name.keytab
The same account and keytab are used to access HDFS.
5. Deploy connector file to Trino cluster
The connector goes to /etc/trino/catalog folder in each Trino node and after Trino cluster has to be restarted.
Comments
comments powered by Disqus